
Xun Jiang
I am a last-year Ph.D. student in the Successive Postgraduate and Doctoral Program at the CFM lab of the University of Electronic Science and Technology of China (UESTC), supervised by Prof. Heng Tao Shen, co-supervised by Prof. Fumin Shen and Prof. Xing Xu. I am also a visiting Ph.D. student of MReal Lab at Nanyang Technological University under the supervision of Prof. Hanwang Zhang. Before that, I earned my bachelor's degree in Software Engineering from UESTC in 2020, where I was recognized as an Honor Graduate.
In the past five years, I have published more than 20 papers on AI/Multimedia flagship conferences and ACM/IEEE transaction journals, including IEEE TPAMI, TMM, TNNLS, TCSVT, TFS, CVPR, ACM MM, AAAI, etc. I am also serving as a journal reviewer for IEEE TPAMI, TIP, TMM, TCSVT, ACM TOIS, TOMM, etc., as well as a Program Committee member for CVPR, ICCV, ECCV, ACM MM, AAAI, WWW, ICASSP, BMVC, etc..
Currently, I'm working on multimodal learning, spatial intelligence (particularly from an egocentric view), and VLM/LLM reasoning enhancement. I am also highly interested in aerial and embodied multimodal perception and understanding. Feel free to contact me for discussion and collaboration!
Email: xun_jiang@outlook.com
Education
|
Dec. 2024 - Dec. 2025 |
Nanyang Technological University (NTU), Singapore
|
|
Dec. 2020 - Present |
University of Electronic Science and Technology of China (UESTC), China
|
|
Sep. 2016 - Jun. 2020 |
University of Electronic Science and Technology of China (UESTC), China
|
News
- [2026/03] Five papers about multimodal learning, egocentric vision, and acoustic UAV localization accepted by ICME 2026! 🎉🎉 Congratulations to all my co-authors!
- [2026/02] Two papers about multimodal learning and multimodal acoustic fied synthesis accepted by CVPR and CVPR Findings 2026!
- [2026/01] Our work on audio and acoustic signal processing was accepted by ICASSP 2026! 🎉🎉 Congratulations to my collaborator Qichen!
- [2025/01] Our work on generalizable egocentric task verification was accepted by IEEE TPAMI!
- [2025/12] Our work on egocentric online action segmentation was accepted by IEEE TMM!
- [2025/11] Two papers about multimodal learning and egocentric video understanding accepted by AAAI 2026! 🎉🎉 Congratulations to Disen and Chong!
- [2025/08] We won ACM MM 2025 Grand Challenge ERR@HRI 2.0! 🎉🎉 Our technical report has been accepted for publication in proceedings.
- [2025/07] One paper about multimodal learning accepted by ACM MM 2025! 🎉🎉 Congratulations to Disen!
Publications
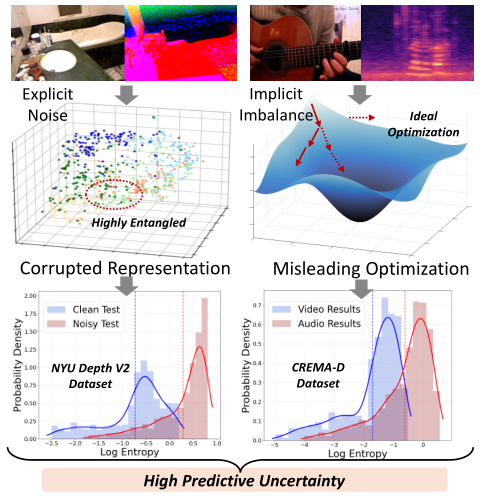
|
Multimodal Learning on Low-Quality Data with Conformal Predictive Self-Calibration Xun Jiang, Yufan Gu, Disen Hu, Yuqing Hou, Yazhou Yao, Fumin Shen, Heng Tao Shen, Xing Xu IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2026 [Paperlink], [Code] Key Words: Multimodal Learning, Low-quality Multimodal Data, Conformal Prediction |
|
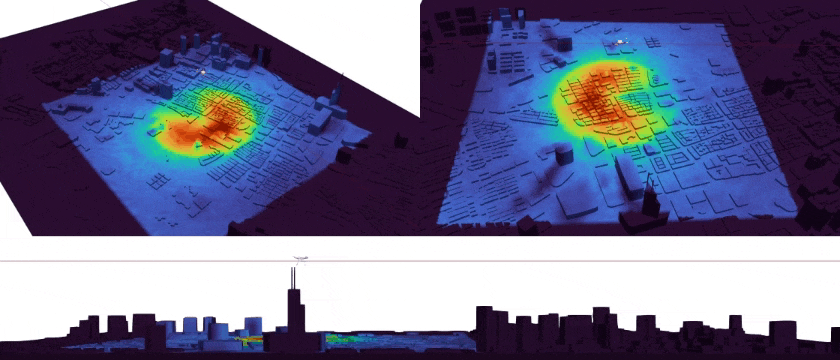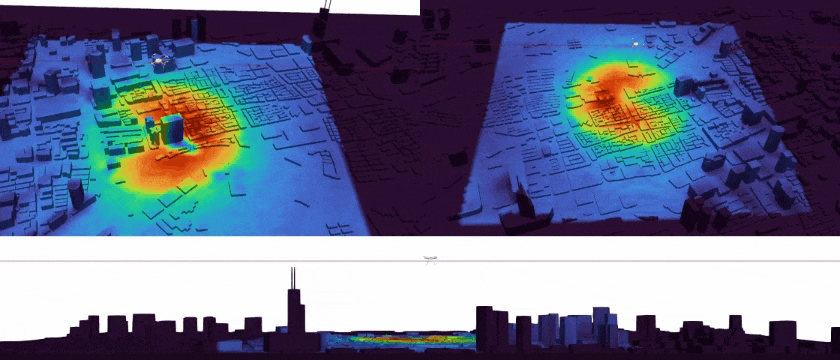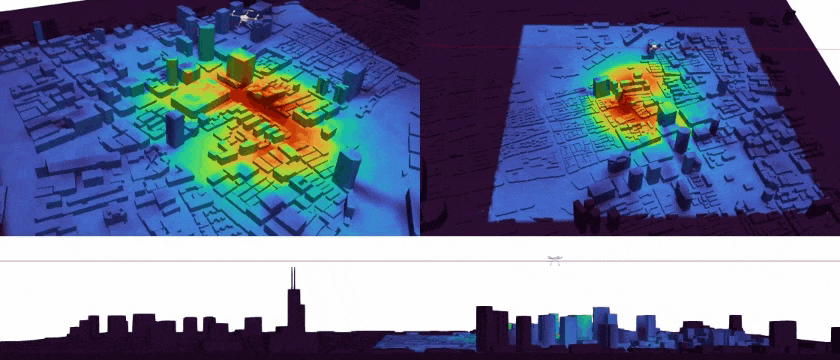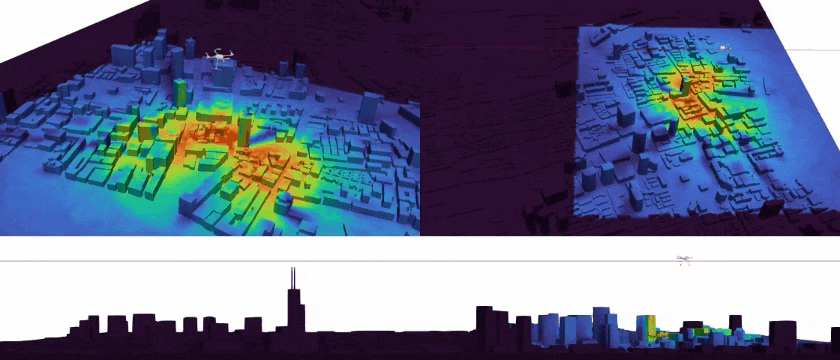
Tracking Environmental Noise for Low-altitude Aircraft with Multimodal Acoustic Field Synthesis Qichen Tan, Kexin Sun, Xun Jiang#(# Corresponding Author) IEEE/CVF Conference on Computer Vision and Pattern Recognition Findings, CVPR Findings 2026 [Paperlink], [Repo] Key Words: UAV Acoustic Field, Multimedia Synthesis, Scientific Visualization |
|
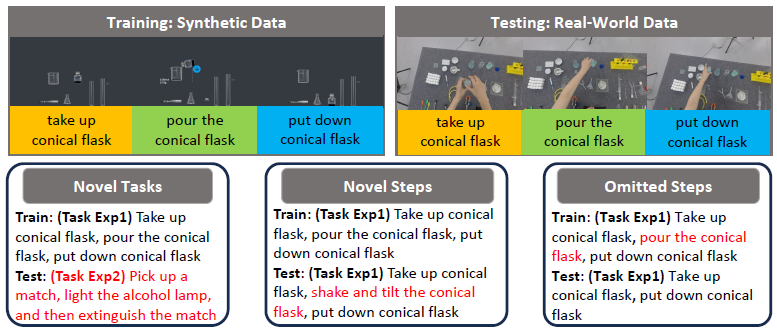
Generalizable Egocentric Task Verification Via Cross-Modal Hybrid Hypergraph Matching
Xun Jiang, Xing Xu, Zheng Wang, Jingkuan Song, Fumin Shen, Heng Tao Shen IEEE Transactions on Pattern Analysis and Machine Intelligence, TPAMI 2026 [Paperlink], [Repo] Key Words: Egocentric Vision, Cross-modal Task Verification, Hypergraph Learning |
|
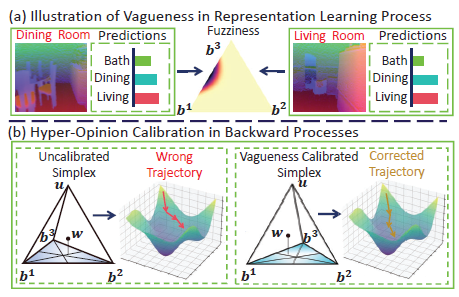
Hyper-Opinion Vagueness Quantification for Robust Multimodal Learning Disen Hu, Xun Jiang, Xiaofeng Cao, Zheng Wang, Jingkuan Song, Heng Tao Shen, Xing Xu AAAI Conference on Artificial Intelligence , AAAI 2026 [Paperlink], [Code] Key Words: Multimodal Learning, Robust Multimodal Learning, Hyper-Opinion Vagueness |
|
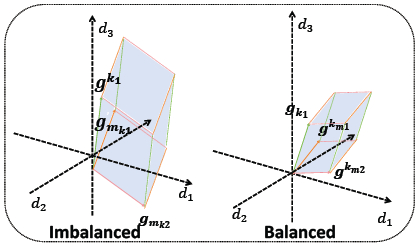
Geometric Gradient Divergence Modulation for Imbalanced Multimodal Learning Disen Hu, Xun Jiang, Zhe Sun, Hao Yang, Chong Peng, Peng Yan, Heng Tao Shen, Xing Xu ACM Internation Conference on Multimedia, ACM MM 2025 [Paperlink], [Code] Key Words: Multimodal Learning, Imbalanced Multimodal Learning, Hyperspace Polyhedron |

|
Procedural Heterogeneous Graph Completion for Natural Language Task Verification in Egocentric Videos Xun Jiang, Zhiyi Huang, Xing Xu, Jingkuan Song, Fumin Shen, Heng Tao Shen IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025 [Paperlink], [Code] Key Words: Natural Language-based Egocentric Task Verification; Heterogeneous Graph Completion; Multimodal Learning; Procedural Task Understanding |
|
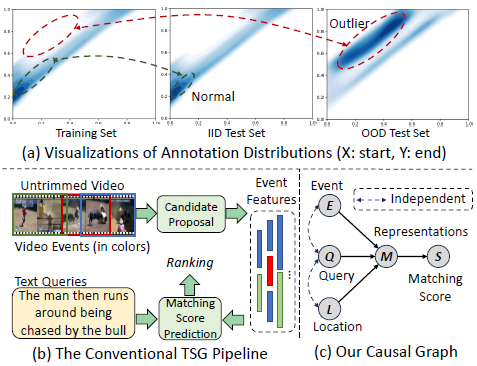
Counterfactually Augmented Event Matching for De-biased Temporal Sentence Grounding Xun Jiang, Zhuoyuan Wei, Shenshen Li, Xing Xu, Jingkuan Song, Heng Tao Shen ACM Internation Conference on Multimedia, ACM MM 2024 [Paperlink], [Code] Key Words: Video Content Understanding, De-biased Video Grounding; Counterfactual Reasoning; Multimodal Learning |
|
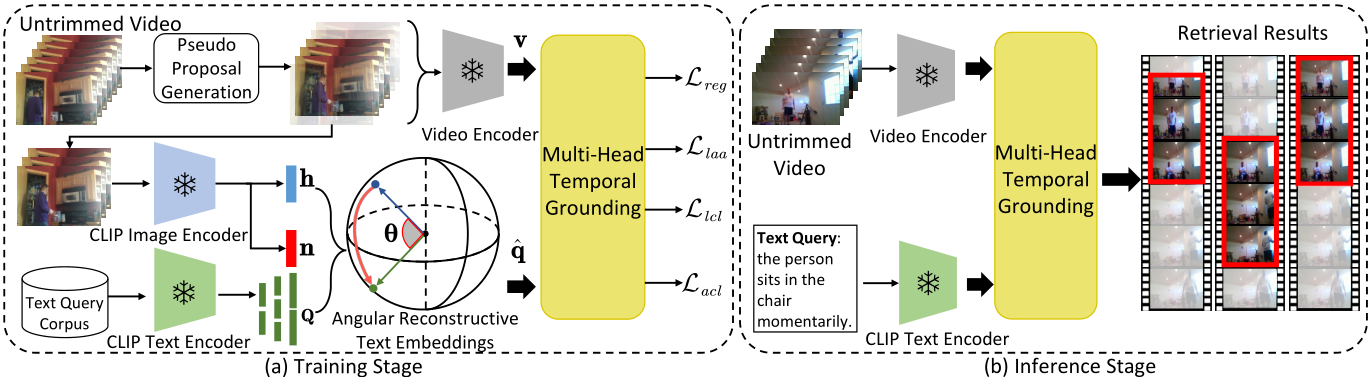
Zero-Shot Video Moment Retrieval with Angular Reconstructive Text Embeddings Xun Jiang, Xing Xu, Zailei Zhou, Yang Yang, Fumin Shen, Heng Tao Shen IEEE Transactions on Multimedia, TMM 2024 [Paperlink], [Code] Key Words: Video Content Understanding; Weakly-Supervised Learning; CLIP |
|
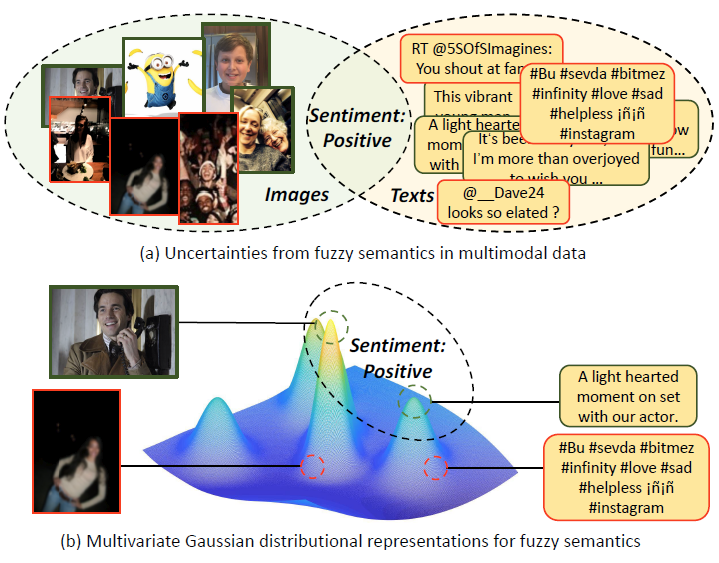
Embracing Unimodal Aleatoric Uncertainty for Robust Multimodal Fusion Zixian Gao*, Xun Jiang* (* Equal Contribution), Xing Xu, Fumin Shen, Yujie Li, Heng Tao Shen IEEE/CVF Computer Vision and Pattern Recognition Conference, CVPR 2024 [Paperlink], [Code] Key Words: Multimodal Learning; Model Robustness; Uncertainty in Deep Learning |
|
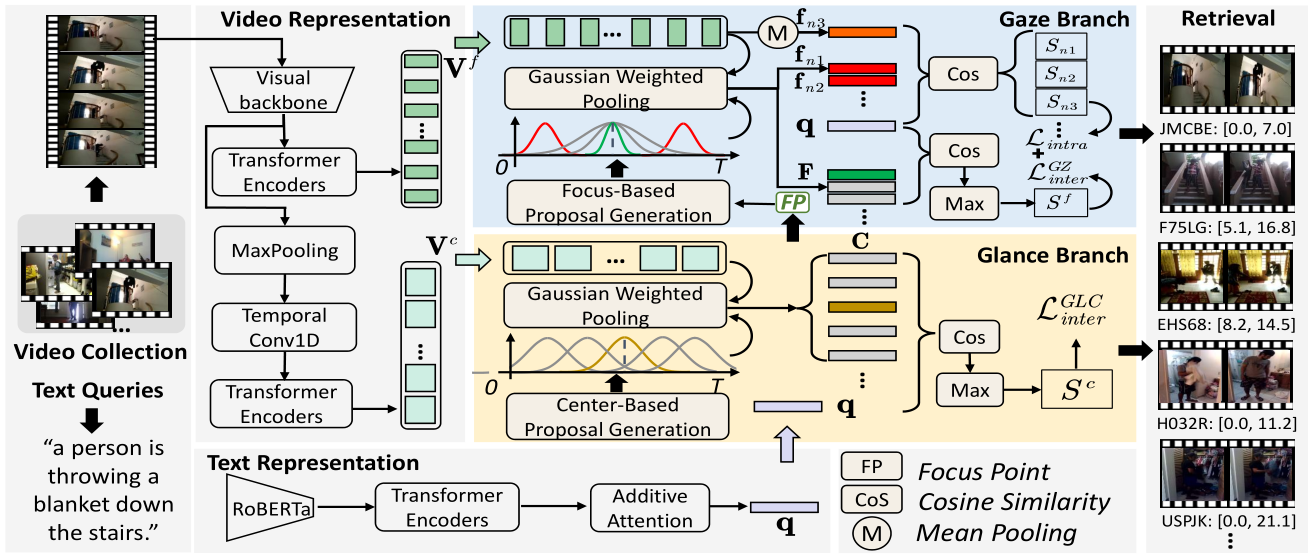
Joint Searching and Grounding: Multi-Granularity Video Content Retrieval Zhiguo Chen*, Xun Jiang* (* Equal Contribution), Xing Xu, Zuo Cao, Yijun Mo, Heng Tao Shen ACM Internation Conference on Multimedia, ACM MM 2023 [Paperlink], [Code] Key Words: Multimedia Retrieval; Video Content Understanding; Multimodal Learning |

|
Multi-Grained Attention Network with Mutual Exclusion for Composed Query-Based Image Retrieval Shenshen Li, Xing Xu, Xun Jiang, Fumin Shen, Xin Liu, Heng Tao Shen IEEE Transactions on Circuits and Systems for Video Technology, TCSVT 2023 [Paperlink], [Code] Key Words: Cross-modal Retrieval; Composed Query-Based Image Retrieval; Multimodal Learning |
|
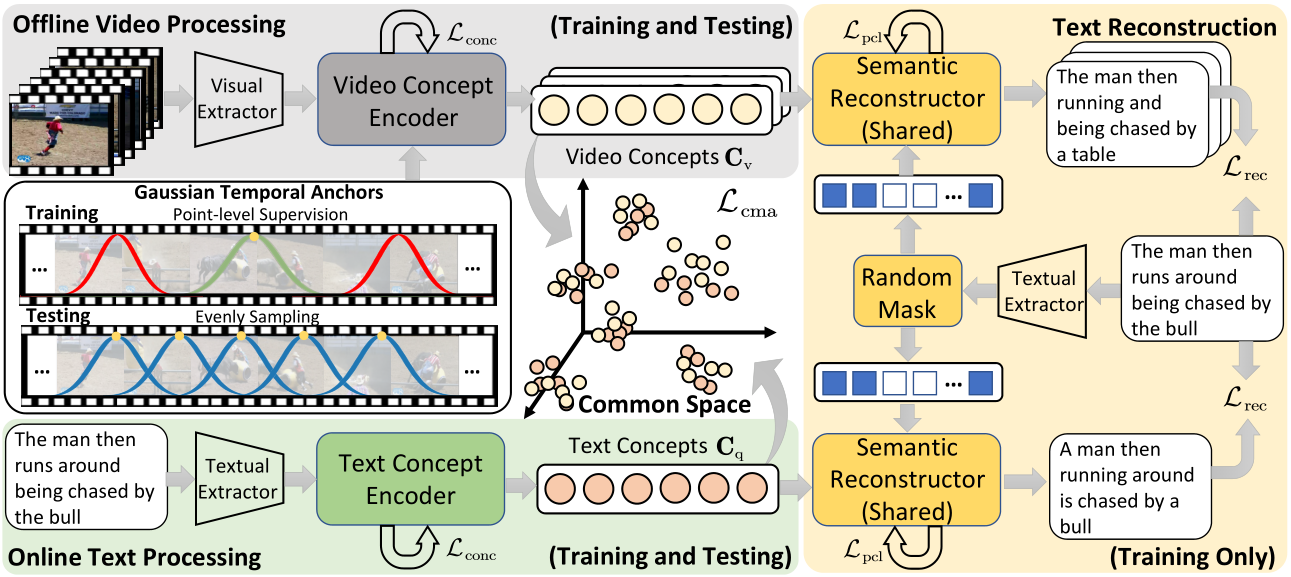
Faster Video Moment Retrieval with Point-Level Supervision Xun Jiang, Zailei Zhou, Xing Xu, Yang Yang, Guoqing Wang, Heng Tao Shen ACM Internation Conference on Multimedia, ACM MM 2023 [Paperlink], [Code] Key Words: Video Content Retrieval; Point-level Supervision; Retrieval Efficiency |
|
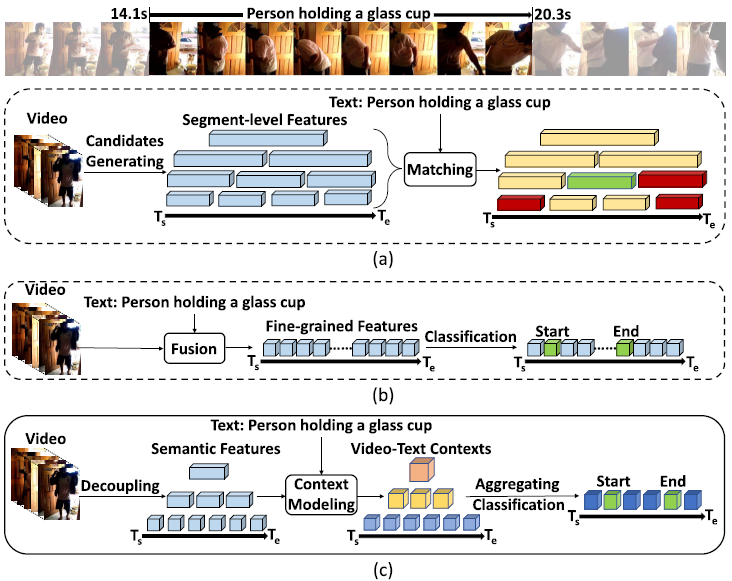
SDN: Semantic Decoupling Network for Temporal Language Grounding Xun Jiang, Xing Xu, Jingran Zhang, Fumin Shen, Zuo Cao, Heng Tao Shen IEEE Transactions on Neural Networks and Learning Systems, TNNLS 2022 [Paperlink], [Code] Key Words: Video Content Understanding; Vision-Language; Multimodal Learning |
|
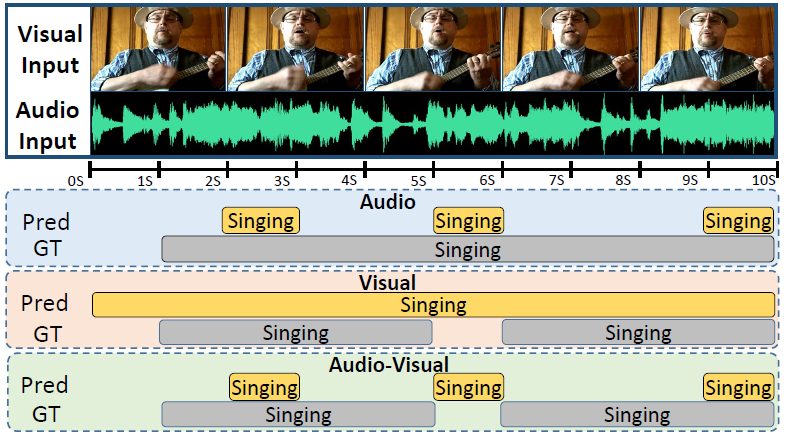
DHHN: Dual Hierarchical Hybrid Network for Weakly-Supervised Audio-Visual Video Parsing Xun Jiang, Xing Xu, Zhiguo Chen, Jingran Zhang, Jingkuan Song, Fumin Shen, Huimin Lu, Heng Tao Shen, ACM Internation Conference on Multimedia, ACM MM 2022 [Paperlink], [Code] Key Words: Video Content Understanding; Action Localization; Audio-Visual Learning |
|
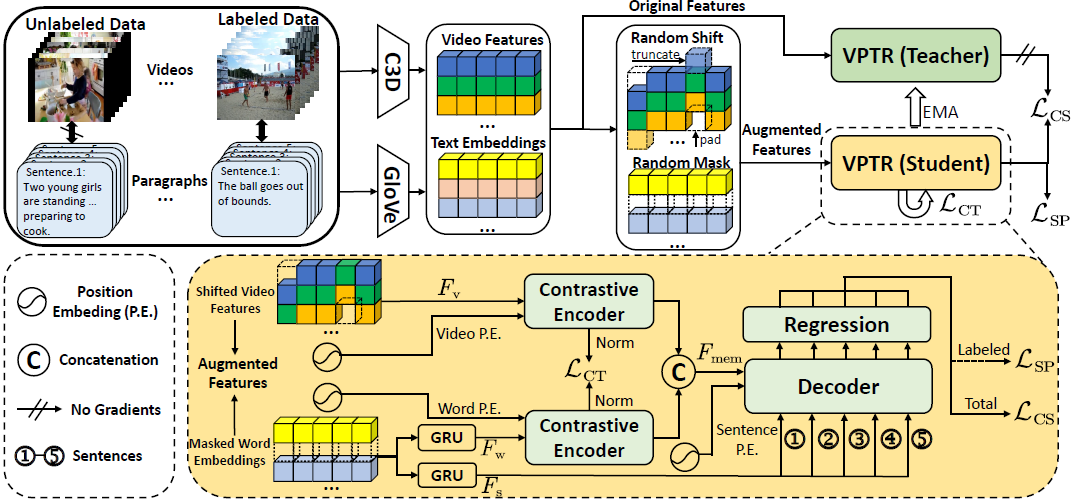
Semi-Supervised Video Paragraph Grounding With Contrastive Encoder
Xun Jiang, Xing Xu, Jingran Zhang, Fumin Shen, Zuo Cao, Heng Tao Shen IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022 [Paperlink] Key Words: Video Content Understanding, Semi-Supervised Learning; Multimodal Learning |
- Outstanding Graduates of Sichuan Province, 2025.12
- First Place at ACM MM 2025 Grand Challenge Track, ERR@HRI 2.0 Sub-Challenge 2, 2025.08
- CAST inaugural Doctoral Student Special Plan of the Young Elite Scientists Sponsorship Program, 2025.01
- Chinese Scholarship Council Scholarship, 2024.07
- Doctoral National Scholarship, 2023.10, 2024.10, 2025.10
- "Academic Newcomer" Ph.D Student Honor Award of UESTC, 2023.04
- ICME Best Student Paper, 2022.07
- "Academic Youth" Postgraduate Student Honor Award of UESTC, 2022.04
- Honor Graduates of UESTC, 2020.06